Overcoming Python's GIL with Cython
Everybody is aware of the infamous Python's GIL. In a nutshell, the GIL is a global variable that prevents multiple threads to be run concurrently by the interpreter. Under some occasions, for certain operations, the interpreter releases the GIL therefore in certain cases this is not a problem. For example, the GIL is released before doing I/O, so I/O bound threads tend to run concurrently. Another example is when doing system calls. Unfortunately, for CPU bound tasks that don't make any I/O or system calls, the GIL prevents different threads from running concurrently, even on multicore CPUs. The astonishing thing is that, in fact, not only different threads do not run concurrently, but they also run slower on multicore CPUs than on single core ones!
I strongly recommend you to watch David Beazley' "Understanding the Python GIL" lecture: it's available as slides or video.
Consider this simple script, that runs twice, sequentially, a busy_sleep, i.e. a function that simulate a CPU intensive task:
This takes 6.7 seconds to run on my laptop. Now consider the threaded version:
One could optimistically expect this script to run in half the time on a multicore processor, or, pessimistically, in about the same time as the sequential version. Instead, it runs in twice the time as the sequential version: 11.1 secs on my laptop. What!?
The picture below shows the CPU usage for seq.py first and par.py second:
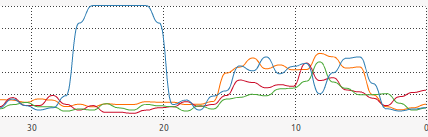
Figure 1: GIL
As explained very well in Beazley's lesson, the threaded version suffers from a very bad behaviour where the OS tries desperately to schedule the two threads on different cores, but, because of the GIL, only one runs at a time whereas the other is moved across cores endlessly…
In fact, a better behaviour is achievable forcing the OS to run the script using just one CPU, using tasksel. This takes as long as the serial version:
$> time taskset -c 0 python par.py taskset -c 0 python par.py 6.64s user 0.01s system 99% cpu 6.662 total
There is a way to overcome the limitation imposed by the GIL for CPU bound threads though: using Cython. Cython offers a wonderful context manager to run instructions without the GIL: with nogil. The catch is that it can only be used to run code that does not touch any Python object.
I've implemented the above example in Cython to show the effect of nogil. (Note: _busy_sleep, by being implemented in pure C, runs faster that its Python's counterpart, so the C version does a bit more useless operations – ** 0.5 a couple of times – to make its busy times comparable).
$> python test_parpyx.py SEQ Elapsed: 10.1856 PAR Elapsed: 5.4503
Yey! The parallel version takes half the time as the sequential one! Note that had we used parpyx.busy_sleep instead of parpyx.busy_sleep_nogil in the =Thread=s we would not have run anything in parallel.
Below is the annotated version of the _busy_sleep function that shows how, by being "all white", no calls to Python's objects are done and, therefore, it can be called with nogil:
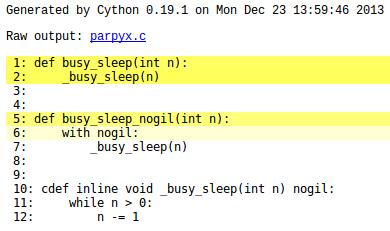
Figure 2: No GIL